


Day 15 of #100daysofnetworks
Context is King! Data Enrichment, Feature Engineering, and Graph ML!

I think most of us have heard the phrase CONTEXT IS KING. There is a good reason for that. Any piece of information can be distorted if taken out of context, or if context is intentionally twisted. We heard it often, that we should not take things out of context. However, techniques for identifying context are rarely discussed outside of journalism.
For this post, I decided to ask ChatGPT what it felt the saying meant.
"Context is king" means that the meaning or importance of something depends on the surrounding information or circumstances. Just like a king rules a kingdom and makes decisions based on the situation at hand, context guides our understanding of words, actions, or situations. Without the right context, things can be easily misinterpreted or misunderstood. So, in everyday life, it reminds us to consider the bigger picture and all the relevant details before making judgments or decisions.
Let’s unpack that:
The meaning or importance of something depends on surrounding information or circumstances.
DANGER: Without the right context, things can be misinterpreted or misunderstood.
This saying reminds us to consider the bigger picture and all relevant details before making judgements or decisions.
In data science and data engineering, identifying and adding context to datasets is known as Data Enrichment. If you are building machine learning models, you may hear of it called Feature Engineering. Feature Engineering is Data Enrichment. In this blog post, I show data enrichment and feature engineering in action.
Why is Data Enrichment Important?
Data enrichment is important for identifying and extracting useful context. In order to identify additional context, domain knowledge is important. For instance, if I want to use graphs to further enrich my data, I need to understand a bit about graphs. Likewise, if I want to use language data to further enrich my data, I should also know a bit about NLP.
But what I have seen often is that language and network data is disregarded. There may be a few reasons for this:
Uncertainty on how network or language data can be useful
Lack of knowledge in how to use network or language data
Lack of experience in using network or language data
So, in Machine Learning, a shortcut can be to disregard all data that is not boolean or numeric. This is lazy and limiting.
For today’s blog post, I’m going to use the Titanic dataset to show that there is usefulness beyond the numeric data. Personally, I enjoy being creative with this dataset, because this dataset contains numeric data, language data, and network data.
However, blog posts and articles I have read on using this dataset tend to prioritize filling in missing values for age.
But the dataset is about the Titanic, and predicting who lives and who dies. Maybe, instead of age, there are other features that are more predictive. Maybe there is more to explore and learn beyond the few numeric and categorical fields!
The point is this: you might not be using the full potential of your datasets, and learning how to use language and network data may make you more effective. It has certainly helped me.
Graph and Language Data
To me, graph and language data are very important data, when present. Language is rich with information, if you know how to use it, and networks/graphs reveal relationships, communities, and node importance. Keep an eye out for language and relationships in your dataset.
For instance, in the Titanic dataset, people have names, and names have titles that can convey age. Also in the dataset, people are assigned rooms, and multiple people can share the same room. We can use this to build a rough social network of the Titanic.
Let’s Dig In
The code for today is available here. You should use it to follow along.
The Titanic dataset has been downloaded from Kaggle and placed into my repo. You can use it for your own experimentation.
Here is what the data looks like:

You can read the data dictionary here, but here are a few initial observations:
passenger_id is most likely useless unless the order that passengers were added had something to do with their class or sex or age.
survived is the label we will use for Machine Learning. 0 means they died, and 1 means they survived.
name is the passenger’s name, and it is language data, which means that NLP may be useful.
sex is the passenger’s sex, and it is categorical, so it should either be label encoded or one-hot encoded.
cabin is the room number, and if cabin and name are used together, we can build a bipartite network and then project it to build a social network.
That’s the original dataset.
So, what does enrichment look like?
When I think of data enrichment, I usually think of the journalistic questions:
Who did what?
What did they do?
When did they do it?
Where did they do it?
Why did they do it?
How did they do it?
If you start with journalistic questions, it gives you a baseline for interrogating your datasets and identifying useful context, or holes where we are missing useful context.
In this dataset, we have the WHO (names) and the WHEN and the WHAT (lived or died), but there are important questions we can ask:
Did age or sex have anything to do with survival? Were women and children saved first? Was this true for all classes or only first class?
Did travelers who traveled alone have less of a chance for survival compared to those who traveled with their families, or was it such a chaotic disaster that family members couldn’t help each other very well?
When families bought tickets for multiple cabins, did the fact that the family was spread out have any effect on survival?
Was saving small children prioritized over older children?
So, the first thing I did is enrich the data by adding some new fields. Please see the code for how.

I think that for a small child, common sense would have it that survival probably has something to do with a parent being present, so I added a few fields to capture that, as well as a few fields to discern whether a person is a child (<=12), small child (<=6), or tiny child (<=2).
Now, to get to the cool stuff, using a Bipartite Graph, I can make very short work of converting our dataset into a rough social network of those who were aboard the Titanic, BUT THIS IS VERY ROUGH. It can be improved with work. This is the quick version. You can read about Bipartite Graphs here.
In a bipartite graph, you have two different types of nodes, where in a social network, you only have one type. As we only have one field for people’s names, we can’t simply turn names into a network.
However, with a bipartite graph, we can project this into a graph of who knows who, based on some similarity. In this case, people shared rooms. This is simple but has one extra step than usual:

First, I import bipartite, then I create a Bipartite Graph using name and cabin. Finally, I project the graph. I am not positive I did the last part correctly, but it seems to work. I’ll dig into that.
As a result, I can see the actual groups of people aboard the Titanic.

Look how the last names are grouped together, for validation.
This turned out better than expected. Note that I am using k_core to remove the isolate nodes. I am only showing the nodes that have one or more edge.
Here is one family:

What is their story?
We can use this graph data for enrichment!
We have a graph, now, and we can use any of the techniques that I have written about in my book or over the last fifteen days on this graph. We can explore the different groups that were present on the Titanic.
To me, that’s much, much, much cooler than just feeding X to Model and getting a 1 or 0. This is life data. These were people! I don’t want to just build models to make predictions. I want to understand what contributed to survival or death. I WANT TO UNDERSTAND, NOT JUST PREDICT.
However, Machine Learning models can tell you WHY they predicted one way or another. This has to do with ML Explainability and Interpretability. Serg Masis wrote a book on this very topic, and this is a must-have, in my opinion.
So, the next thing I do is convert the Graph into node embeddings, so that I can merge it back with the dataset, as enriched data.
I gave the embedding columns names of g_eb_#, where the g stands for graph, eb stands for embedding, and the number is the embedding number. I used Karate Club for this, and you can learn more about Karate Club in this book. I also describe how to do this in my book.
I then merge these embeddings with the previously enriched data, and then used the data to build a Machine Learning Model.
What Was Important?
Some Machine Learning models will tell you what they found to be important in making predictions. These are the top twenty features my baseline model found to be important.
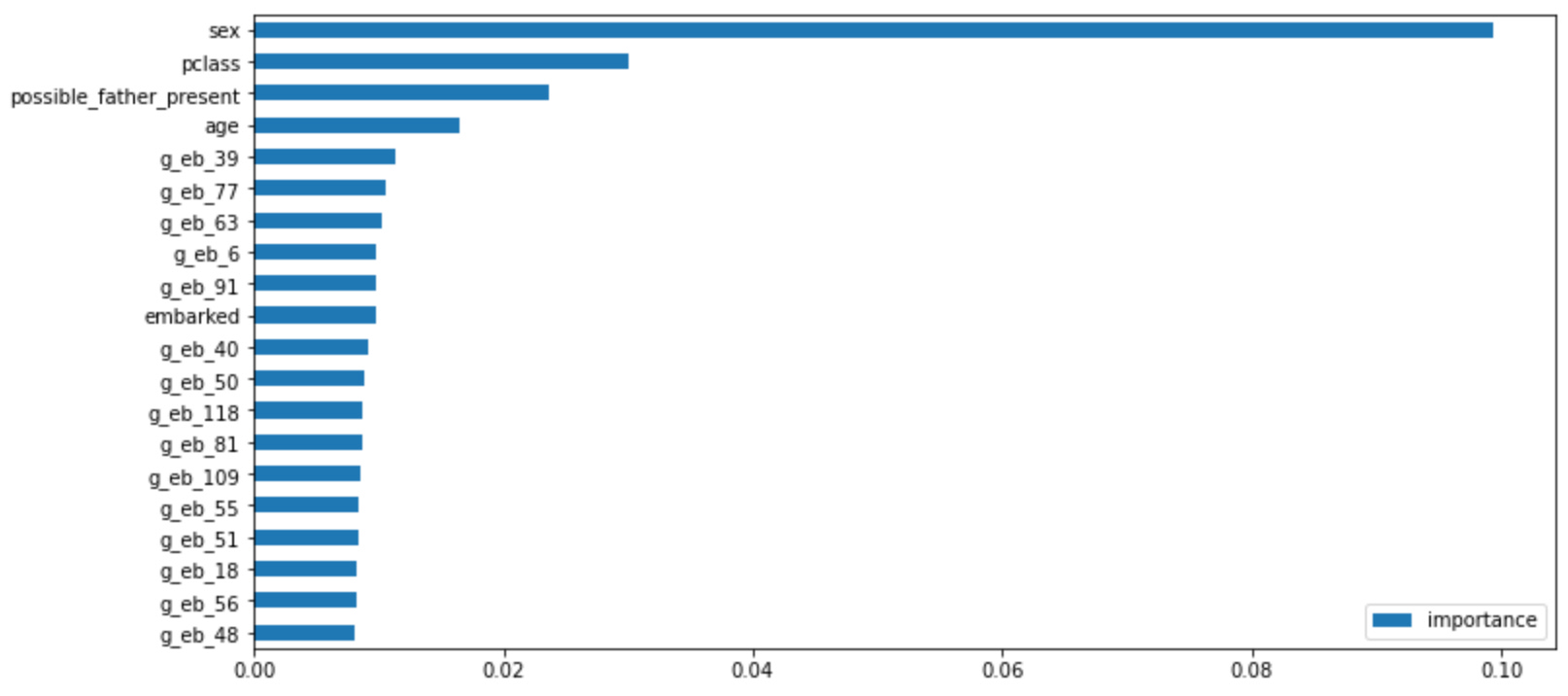
Note that out of all of the fields, only sex, pclass, age, and embarked were the most important from the original data.
Note also that possible_father_present shows as the third most important feature. That’s surprising! My hunch was that the mother would matter more for survival. That’s an interesting insight, if correct.
And then note that the other fifteen important features were graph features!
However, this model is not great. It was built quickly, in minutes, for this example. I am not competing on Kaggle. This is for illustrative purposes, to show that enriching data is useful and often overlooked.
This is my Why
This is the actual reason I wrote my book: I wanted people to understand the added potential that comes with enriching your data, beyond surface level feature engineering. I want people to understand that you don’t just disregard data that you don’t know how to use. It can be useful, for additional context, if you learn to use it. I want people to begin to see networks everywhere, even when it is not obvious (people and cabins in the dataset).
Context is king, and more context can make better models and higher quality artificial intelligence. However, context fields can also be useful in analysis to be able to answer more interesting questions.
For instance, why did it matter so much that a father was present rather than a mother? Is this an error or an insight? The best part of data science is that a question will lead to more questions and then to greater understanding.
That’s All, Folks!
That’s all for today! Thanks for reading! If you would like to learn more about networks and network analysis, please buy a copy of my book!