


Day 10 of #100daysofnetworks
Wikipedia Content Crawler and Entity Networks!

If you would like to learn more about networks and network analysis, please buy a copy of my book!
Hi everyone. I’m very excited about today’s post, for two reasons:
I’ve created a Wikipedia content crawler, and you can use it.
I’m going to show you how to convert raw text into entity graphs.
Wikipedia Content Crawler
The github for the Wikipedia Content Crawler has been linked to above. It currently takes a .csv edgelist as input, converts the edgelist to a graph, and then crawls content for each node in the graph.
However, you can tweak the code to pass in a list of pages, if you wanted to. The more pages you pass in, the longer the crawl will take.
For today’s post, I passed in a very simple edgelist for a graph with 41 nodes and 167 edges. The edges don’t matter. The nodes get crawled. As the nodes are Wikipedia pages, this means that the crawler crawls wikipedia, builds a dataset, and then saves it to file.
This is a useful tool for knowledge discovery on Wikipedia. It is also a useful tool for learning Natural Language Processing and Data Science, as the crawler returns text content, all web links, and more.

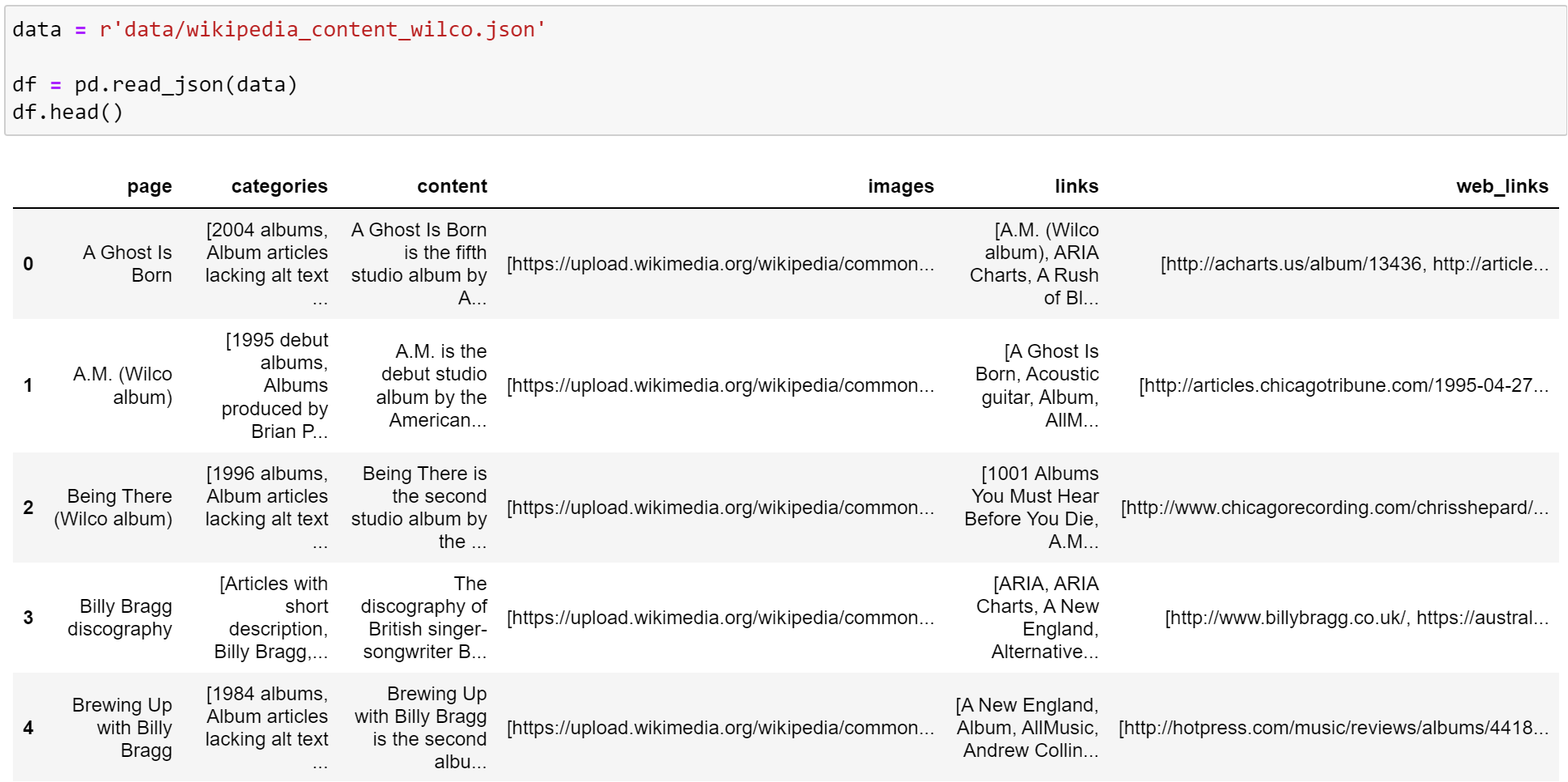
The above image is a preview of the crawled Wilco data. There’s a few things to notice:
Page is the page title.
Categories is a list. Categories could be useful in building other types of networks.
Content is all of the text on a Wikipedia page.
Images are images found on the Wikipedia page.
Links is a list, pointing to other Wikipedia pages. We use this in our networks.
Web Links is a list of website links. We can use this to make other networks.
So, very quickly, in #100daysofnetworks, we have started with a theme (Wilco), created a network of Wikipedia pages that are about Wilco, removed junk nodes, and then crawled text from Wikipedia for the relevant pages. We have essentially created a clean dataset of richer content for analysis. That’s powerful.
Converting Text to Entity Graphs
Just FYI, all datasets created during in #100daysofnetworks are accessible here. You can dive into analyzing any of these.
Using the freshly crawled Wilco content, I now have rich and useful data for Natural Language Processing. Now, I can show you the magic of Natural Language Processing and Network Science combined.
I can take ANY TEXT and convert it into an Entity Network. We can explore these Entity Networks using Social Network Analysis and Network Science.
I literally mean it when I say I can do this with any text. After my book was published, I found a 600 page PDF file on the internet. After converting the PDF to text, the conversion went perfectly, and it only took a few minutes.
Here is what I did (see code here):
Load our content dataset
Load spaCy model
Combine all ‘content’ text into one ‘text’ variable.
Using spaCy, do Named Entity Recognition (NER) and extract entities
Use the extracted entities to create an Entity Network
This approach is written about in my book, so you should buy a copy to learn more. In fact, today’s code was taken from my book’s Github, to save time.
What is Named Entity Recognition (NER)?
Other than approaches for similarity, Named Entity Recognition (NER) is probably my favorite NLP technique. NER uses Machine Learning to identity people, places, organizations, and much more from text.
That’s it. You pass in text, and you get entities back.
With these entities, you can tell who a piece of content is about, automatically. This is powerful for data mining and information extraction.
Please read my book, ask ChatGPT, or spend some time researching NER. It is too useful to ignore, if you work in Natural Language Processing or Data Science.
Let’s See the Results
Today’s post is a show-and-tell. I wanted to announce the crawler that I built, as that will be useful to others, and I want to give a preview of what you can do with the data. You can do a lot more. This is the TOP of the rabbit hole. We haven’t even jumped in. These are just options.
First, I load the data:
Next, I combine the content into a text field and extract all entities:

Then I use those entities to create an Entity Graph:

And finally, we have a graph that we can explore. Notice that we went from 41 nodes to 914 nodes? We went from a small graph to a larger and denser graph, all related to Wilco. Our larger graph should serve us wonderfully for knowledge discovery.
Let’s Explore a Bit!
It’d be really boring to end today’s post without at least exploring a bit. What can I see, in this new network?

I can see that it’s pretty complex, as expected. I can see that there are no isolates, due to the nature of how the graph is constructed. I can see that the network gets denser and denser as we look closer to the core.
What does the core itself look like? I’ve mentioned that I usually take a look at the core to get an understanding of which nodes are most influential to a network.

The core is beautiful.
Which nodes are most important in the network?

STOP FOR A SECOND. Truly appreciate what has happened. For this bar chart to exist, we have fused NLP with Network Science. NLP took care of the entity extraction for the graph construction, and Network Science gives us the ability to explore node importance. This is the marriage of NLP and Network Science.
This looks great. There are some names I don’t recognize, and that’s great.
Here are the node Betweenness Centralities.

This is the Beginning
The content crawler unlocked new analysis for us, allowing us to use NLP techniques and fuse them with Network Science. Use the crawler, get interesting data, explore it and learn to analyze it.
Thank you for reading today’s post! We made it to day 10!
If you would like to learn more about networks and network analysis, please buy a copy of my book!